

Comparing ABBYY FlexiCapture with FineReader Server: Similarities and Differences
Learn about the differences between server based OCR and intelligent data capture.
Summary: ABBYY FlexiCapture has many functions in common with ABBYY FineReader Server (formerly branded as Recognition Server). However, each product is designed with unique functions in mind which companies must consider when evaluating solutions to their document capture and OCR requirements. A comparison of the functions between FlexiCapture and FineReader Server is most easily done by considering a list of functional criteria alongside a high level overview of each product.
Overview of ABBYY FineReader Server Functions and Use Cases
ABBYY FineReader Server is a software application whose primary function is the conversion of documents and images to searchable, OCR formats. The software operates on a server to provide OCR conversion of documents on a large-scale basis to meet the processing time-frame requirements for companies requiring a scalable solution. It can also provide a cost-effective means for companies to capture and manually index documents across the enterprise either through scanning of paper documents or processing of electronic files and images. FineReader Server does not provide for the conversion of handwriting or check mark values.
Typical Use Cases for ABBYY FineReader Server
- Monitor a variety of shared folders on a network and convert images and documents to image over text PDF. When a new file is added to a folder, it is converted to a text-searchable version and then moved to the corresponding export folder while maintaining the original sub-folder designation. The export file would maintain the legal integrity of the original image file while adding a searchable text layer behind the image in the PDF file in the export folders.
- Provide a means for a user to scan a particular type of document from a list of possible types, then present the user with a list of pre-configured index fields for that particular document. Allow the user to correct any errors created during the OCR process and also let them click on the document itself to lasso and automatically OCR the desired field values.
- Monitor an IMAP email inbox and convert any incoming file attachment to a text searchable version and export to a pre-configured folder or email location. For example, the server could monitor a certain email address and then convert any incoming file attachment to a Microsoft Word version of the document. The document could then be returned to the original sender in Microsoft Word format.
- Monitor a Microsoft SharePoint Server library and automatically check out non-OCR versions of documents and then check in a new, text searchable version.
The image below shows the relationship between the components in FineReader Server.

Overview of ABBYY FlexiCapture and Typical Use Cases
ABBYY FlexiCapture is primarily an enterprise level data extraction software application which also provides OCR functions. FlexiCapture provides a means to automatically extract data from documents based upon the establishment of rules including keywords and location of the information on a page. FlexiCapture is also available in special, ready to run solution packages such as FlexiCapture for Invoices and FlexiCapture for Mailrooms. Although the solution heavily relies upon the use of the same OCR technology found within FineReader Server, and it can export a text searchable version of a document, it’s core function is the following: classification of documents (determining their type), matching these document classes to the corresponding data extraction rules, and then exporting the data somewhere such as a database, XML file, Microsoft Excel, or multiple locations at the same time. FlexiCapture provides for the extraction of typed text, barcodes, handwriting and check mark field values.
When considering FlexiCapture, companies must consider whether the document is structured, meaning the field data is always located in the same position from document to document, or whether it is unstructured. An example of a structured document is a W-2 form, whereas a good example of an unstructured document is an invoice in which varying amounts of line items are found from one invoice to another. Additionally, each vendor produces invoices in varying formats and different vendor’s invoice are substantially different from one another.
FlexiCapture contains some unique features including the ability to classify, extract, and then compare extracted field values from document sets. For example, a loan application may consist of a half dozen documents, some of which contain a SSN. A rule can easily be configured to compare the SSN’s from each of the documents containing a value for this field and then present any errors to the operator during the document verification phase.
Typical Use Cases for FlexiCapture
- Monitor a shared network folder or email address for incoming documents. Classify the incoming document to determine which data will be extracted according to the preconfigured rules then automatically extract these data values from the document. Finally, export a text searchable PDF version of the document to a content management system and populate the required field values with data extracted from the documents. Provide users with a means of correcting the extracted data along with queues for managing exceptions to pre-programmed rules within the document workflow process.
- Provide an accounts payable department with the means to automatically extract data from invoices received by paper mail and email. Present AP users with the ability to provide general ledger lookups along with 2-way matching of invoice line items against the corresponding purchase from the accounting or ERP system. Export a text searchable version of the invoice to the accounting system. Provide AP supervisors with a means to approve invoice payment based upon dollar amounts or other rules. Additionally, provide accounts receivable departments with a means of automatically processing incoming purchase orders.
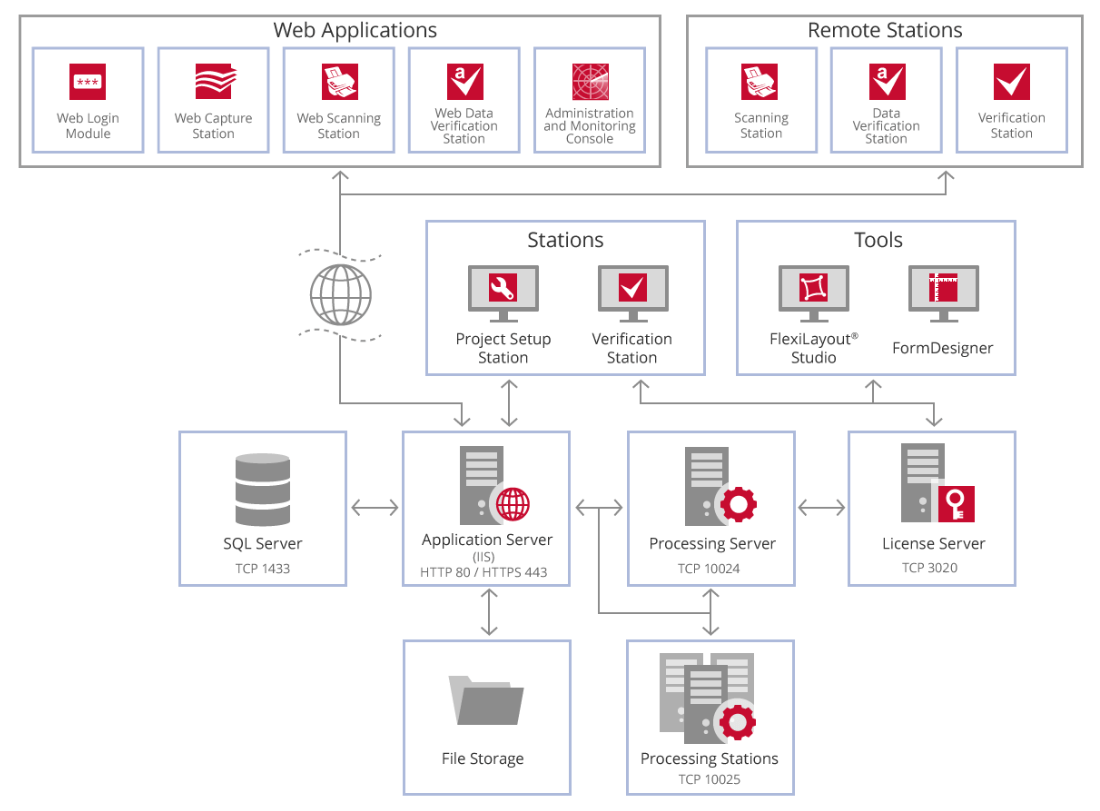
The image below shows the stations and their relationships in ABBYY FlexiCapture.
Similarities and Differences Between FlexiCapture and FineReader Server by Function or Architecture
| Software Function or Architecture | ABBYY FlexiCapture | ABBYY FineReader Server |
| Bulk, high-volume unattended OCR conversion of documents. | No. This is possible, but FlexiCapture is uniquely designed to extract documents. |
Yes. This is a core function and high page counts are affordable. Additionally, processing stations can be added for no additional charge which scale the processing speed in proportion to the number of stations added. |
| Extract key values from a wide variety of different documents automatically and then export the data to a content management system. | Yes. This is a core function. Documents are extracted based upon rules inside of what is called a “document definition.” For unstructured documents additional specifications are provided within a tool called Flexilayout Studio. |
No, not automatically, with the qualifications noted below. Index values can be added by clicking on the index field and then by lassoing the value on the image displayed during the document indexing function, a process referred to by ABBYY as “click and key.” In some cases scripts can be developed to extract certain common values from documents and then automatically applied to the document. These functions will be further expanded in the upcoming version 5 of the product. |
| Web-based client for performing scanning, verification, indexing and administrative functions. | Yes. This is a core function of the Distributed version of the application. All client functions are available in web based versions except for the configuration of the document definitions and FlexiLayouts. The base system comes with one of each kind of client and more stations can be easily added. In addition to the scanning and verification web stations, a combined station is available that provides both scanning and verification functions into one easy to use application. |
No. All stations in FineReader Server are “rich client,” meaning they are installed on computers running Microsoft Windows through the add / remove programs function. As with FlexiCapture, the base system comes with one of each type of client, additional stations can be added. |
| Microsoft Active Directory Integration for User Login | Yes. This is a core function for all of the client workstations for both the thick (rich) clients and the web based version. |
Yes, with qualification as noted below.Access is provided for users of each of the three rich client workstation types (scanning, verification, indexing) through the assignment of named users in the admin and monitoring station. Permissions for these different tasks (such as administration, verification and indexing) can be assigned through Microsoft Active Directory user groups. The admin function is handled with a snap-in for the Microsoft Management Console (MMC). |
| Processing of Digitally Born Documents (such as Microsoft Word documents). | Yes. This is a core function of the system and like FineReader Server the system can use either Microsoft Office or Libre Office to provide access to these functions. |
Yes, within certain limits. FineReader Server can process digitally born documents through its built-in integration with a rendering engine including either Microsoft Office or Libre Office. |
| Availability of Web Services API. | Yes.
This is included in the base version of the product. |
Yes. This is available as an add-on component. |
| Automatic Classification of Documents | Yes. This is a core function. |
No, except this can be done through the use of a barcode separator sheet to explicitly specify the document type. |
| Automatic Separation of Documents. | Yes. This is a core function. |
Yes, but not automatically in all cases. Documents can be separated automatically through the use of barcodes and blank pages. Barcodes can be used to specify the type of document. |
| Automatic Indexing of a Document | Yes. This is a core function. |
No, not automatically, except in certain cases with scripting. A degree of automatic indexing is being released in an upcoming version, however this is for basic indexing functions. |
| Ability to “Train” the System for the Addition of New Fields | Yes. This is a core function. Field types are specified in the document definition without a region (location on the document). Then several example documents are run and the field values selected. Additional variations of the forms can be added at this stage or later as they are encountered. |
No. Indexing fields are preconfigured for all of the various document types. Fields values are not automatically populated but are instead added through the use of the indexing station where the user first select the field and then uses the “click and key” method to populate the value. |
We will be glad to answer any questions you have regarding this article explaining the differences between ABBYY FlexiCapture and ABBYY FineReader Server.
Hi
Have you encountered issues on difficulty in OCRing documents because of renderable text in the document? We got that issue and we do not know how to resolve it. ABBY does not OCR the document and sometimes only OCR a bit of the document.
After talking with you I see an article from Adobe about the problem:
[url=https://helpx.adobe.com/acrobat/kb/error-could-perform-recognition-acrobat.html][/url]
This would require further investigation by talking with ABBYY Support. I am surprise that we have not yet run into this yet and am interested to hear about what you find out.